YOLO-World introduces an innovative framework for real-time object detection, expanding the capabilities of traditional YOLO models through vision-language integration. This approach allows for dynamic, open-vocabulary object recognition, significantly enhancing detection performance across diverse datasets.
What is YOLO-World?
YOLO-World is a cutting-edge object detection framework that uses both vision and language models to recognize a broad range of objects, not just those it was specifically trained to find. By using descriptions in language, it can identify many different items more accurately and flexibly.
New object detector paradigm
The YOLO-World framework facilitates the dynamic specification of classes via custom prompts, enabling users to customize the model according to their unique requirements without retraining. This feature is helpful for adjusting the model to new areas or specific tasks that weren't initially included in the training data.
Comparison with Detection Paradigms. [1]
Traditional Object Detector
These detectors are designed to identify objects within a fixed, pre-defined vocabulary, which is determined by the categories available in the training datasets, such as the 80 categories of the COCO dataset. This fixed vocabulary restricts the detector's application in scenarios that require recognition of objects outside this set vocabulary, limiting its adaptability and utility in open-world scenes.
Previous Open-Vocabulary Detectors
Earlier approaches to open-vocabulary detection sought to address the limitations of fixed vocabulary detectors by creating large, heavy detectors capable of processing a broader range of objects. These detectors tend to have a strong capacity due to their size but come with the drawback of requiring simultaneous encoding of images and text for prediction.
This process, while effective in broadening the range of detectable objects, is computationally intensive and impractical for real-time applications due to its time-consuming nature.
YOLO-World
YOLO-World introduces a paradigm shift by demonstrating the effectiveness of lightweight detectors in performing open-vocabulary detection. Unlike previous approaches that rely on large models and online vocabulary encoding, YOLO-World employs a "prompt-then-detect" method that significantly improves inference efficiency.
This approach involves generating prompts based on user needs, which are then encoded into an offline vocabulary. The model can re-parameterize this offline vocabulary as part of its weights, allowing for faster deployment and acceleration.
This method represents a significant advancement in making open-vocabulary object detection more practical and applicable in real-world situations, where quick and accurate detection is paramount.
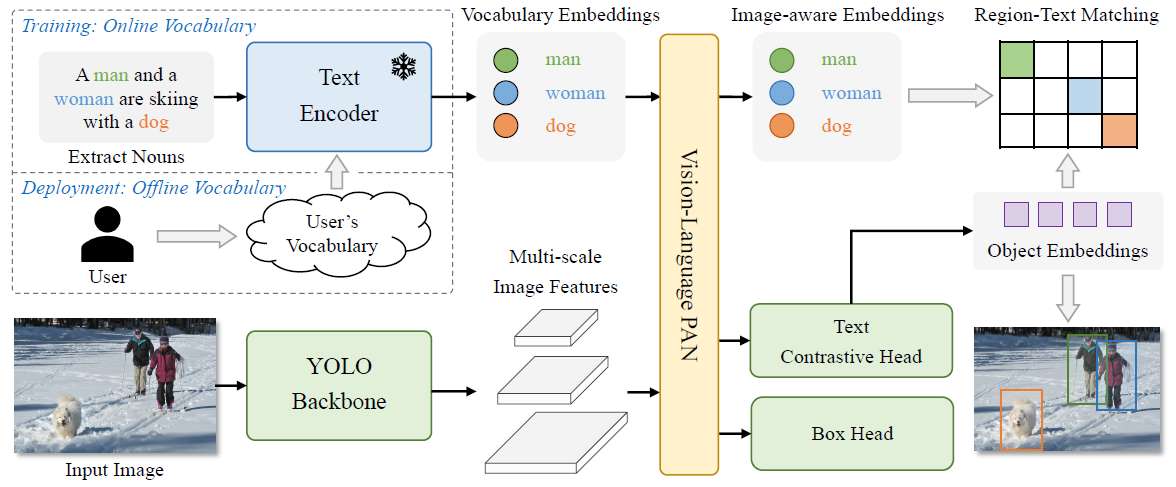
YOLO-World Architecture
At its core, YOLO-World integrates a YOLO detector, a Text Encoder, and a novel Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN), focusing on enhancing text and image representation through cross-modality fusion. Here's a breakdown of its components:
Overall Architecture of YOLO-World. [3]
YOLO Detector: Developed based on YOLOv8, it comprises a Darknet backbone for image encoding, a path aggregation network (PAN) for generating multi-scale feature pyramids, and a head for bounding box regression and object embeddings.
Text Encoder: Utilizes a Transformer text encoder, pre-trained by CLIP, to transform input text into text embeddings. This encoder is specifically chosen for its superior visual-semantic capabilities, allowing for a more effective connection between visual objects and texts.
Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN): This component is crucial for the interaction between image features and text embeddings, enhancing the visual-semantic representation for open-vocabulary capability. The architecture follows top-down and bottom-up paths to establish feature pyramids with multi-scale image features. It introduces the Text-guided CSPLayer (T-CSPLayer) and Image-Pooling Attention (I-Pooling Attention) for enriching the fusion between image and text features.
During inference, the offline vocabulary embeddings can be re-parameterized into weights of convolutional or linear layers for deployment, optimizing the process for real-time applications. This approach significantly enhances the flexibility and efficiency of the YOLO-World architecture, allowing it to perform open-vocabulary object detection with improved accuracy and speed.
Real-Time Processing: YOLO-World capitalizes on the computational efficiency of Convolutional Neural Networks (CNNs) to deliver swift open-vocabulary detection. This makes it an ideal solution for industries requiring instantaneous object detection and analysis.
Efficiency and High Performance: YOLO-World significantly cuts down on computational needs and resources, offering a high-efficiency solution that outperforms traditional models like SAM, all while maintaining a much lower computational cost. This efficiency is achieved without compromising the model's performance, allowing for real-time operations with high accuracy.
Benchmark Superiority: YOLO-World excels in speed and efficiency against other open-vocabulary detectors like the MDETR and GLIP series, as demonstrated across standard benchmarks. Its effectiveness, powered by a single NVIDIA V100 GPU, highlights the model's advanced design and capabilities.
Speed-and-Accuracy Curve. [1]
Inference with Offline Vocabulary: Utilizing a "prompt-then-detect" approach, YOLO-World boosts operational efficiency by leveraging pre-computed offline vocabulary embeddings. This method enables the integration of custom prompts, such as captions or categories, directly into the model, simplifying the detection process by eliminating the need for real-time computation for each input.
Advanced Detection with YOLOv8: Leveraging the foundation of Ultralytics YOLOv8, YOLO-World incorporates the latest in real-time object detection technology. This ensures outstanding open-vocabulary detection performance, characterized by unmatched accuracy and speed.
Versatile Application: Designed innovatively, YOLO-World unlocks new potentials in a variety of vision tasks, showing significant speed improvements over existing approaches. Its versatility renders it suitable for a wide range of practical uses, enhancing its value beyond conventional object detection scenarios.
Easily run YOLO-World Object Detection
Setup
With the Ikomia API, you can effortlessly detect object on your image with YOLO-World using just a few lines of code.
To get started, you need to install the API in a virtual environment [2].
pip install ikomia
Run YOLO-World with a few lines of code
You can also directly charge the notebook we have prepared.
pip install ikomia
Run YOLO-World with a few lines of code
You can also directly charge the notebook we have prepared.
from ikomia.dataprocess.workflow import Workflow
from ikomia.utils.displayIO import display
# Init your workflow
wf = Workflow()
# Add algorithm
algo = wf.add_task(name="infer_yolo_world", auto_connect=True)
algo.set_parameters({
"model_name": "yolo_world_v2_x",
"prompt": "person, cup, laptop, glasses, plant",
"max_dets": "100",
"conf_thres": "0.1",
"iou_thres": "0.25"
})
# Run on your image
wf.run_on(url="https://images.pexels.com/photos/3184296/pexels-photo-3184296.jpeg?cs=srgb&dl=pexels-fauxels-3184296.jpg&fm=jpg&w=1920&h=1280")
# Display your image
display(algo.get_image_with_graphics())
List of parameters:
model_name (str) - default 'yolo_world_m': Name of the YOLO_WORLD pre-trained model. Other model available:
- yolo_world_s
- yolo_world_v2_s
- yolo_world_m
- yolo_world_v2_m
- yolo_world_l
- yolo_world_v2_l
- yolo_world_l_plus
- yolo_world_v2_l_plus
- yolo_world_l_x
- yolo_world_v2_l_x
conf_thres (float) default '0.1': Box threshold for the prediction [0,1].
iou_thres (float) - default '0.25': Intersection over Union, degree of overlap between two boxes [0,1].
max_dets (int) - default '100': The maximum number of bounding boxes that can be retained across all classes after NMS (Non-Maximum Suppression). This parameter limits the total number of detections returned by the model, ensuring that only the most confident detections are retained.
cuda (bool): If True, CUDA-based inference (GPU). If False, run on CPU. If using a custom model:
model_weight_file (str, optional): Path to model weights file .pth.
config_file (str, optional): Path to model config file .py.
Original image source [3]
Build your own workflow with Ikomia
In this tutorial, we have seen the process of developing a workflow for zero-shot object detection using YOLO-World. The Ikomia API helps in streamlining the creation of computer vision workflows, allowing you to chain algorithms from different frameworks and offering the flexibility to experiment with various parameters for optimal results.
Resources:
Explore the Ikomia HUB, which presents a wide array of algorithms accompanied by accessible code snippets, facilitating easier experimentation and assessment.
Find detailed guidance on leveraging the API to its fullest potential within the Ikomia documentation.
Experience Ikomia STUDIO, a key part of the ecosystem that provides a more visual and intuitive method for image processing. It features a user desktop application that mirrors the capabilities of the API, enhancing the experimentation process.















.svg)


