
Easy stable diffusion inpainting with Segment Anything Model

Image segmentation is a critical task in Computer Vision, enabling machines to understand and analyze the contents of images at a pixel level. The Segment Anything Model (SAM) is a groundbreaking instance segmentation model developed by Meta Research, which has taken the field by storm since its release in April 2023.
SAM offers unparalleled versatility and efficiency in image analysis tasks, making it a powerful tool for a wide range of applications.
SAM was specifically designed to address the limitations of existing image segmentation models and to introduce new capabilities that revolutionize the field.
One of SAM's standout features is its promptable segmentation task, which allows users to generate valid segmentation masks by providing prompts such as spatial or text clues (feature not yet released at the time of writing) that identify specific objects within an image.
This flexibility empowers users to obtain precise and tailored segmentation results effortlessly:
1. Generate segmentation masks for all objects SAM can detect.
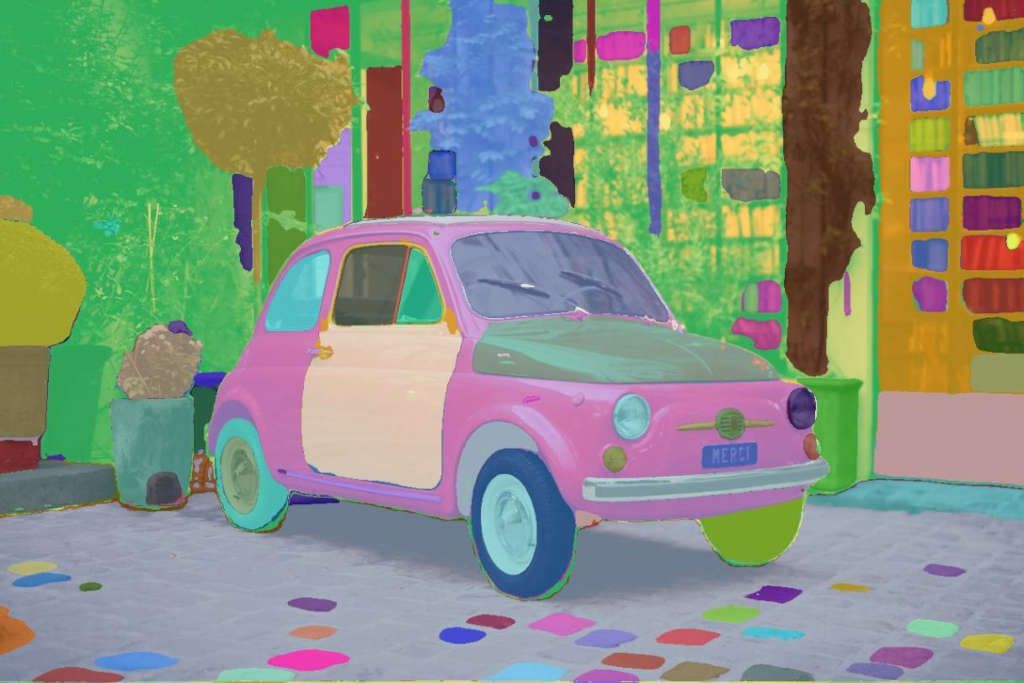
2. Provide boxes to guide SAM in generating a mask for specific objects in an image.

3. Provide a box and a point to guide SAM in generating a mask with an area to exclude.
.jpg)
At the core of SAM lies its advanced architecture, which comprises three key components: an image encoder, a prompt encoder, and a lightweight mask decoder. This design enables SAM to perform real-time mask computation, adapt to new image distributions and tasks without prior knowledge, and exhibit ambiguity awareness in segmentation tasks.
By leveraging these capabilities, SAM offers remarkable flexibility and adaptability, setting new standards in image segmentation models.

The SA-1B dataset, integral to the Segment Anything project, stands out for its scale in segmentation training data. It consists of more than 1 billion masks from 11 million diverse, high-quality images, making it the largest dataset of its kind.
The images, which are carefully selected and privacy-conscious, offer a wide variety of object categories. This extensive and varied collection of data provides the foundation for SAM (Segment Anything Model) to develop a nuanced understanding of different objects and scenes.
As a result, SAM exhibits enhanced generalization abilities, enabling it to perform with notable precision across various segmentation challenges. This dataset not only supports SAM's advanced capabilities but also marks a significant advancement in the resources available for image segmentation tasks.
The development and structuring of SA-1B involve a three-stage data engine process that addresses the scarcity of segmentation masks available on the internet. This process starts with model-assisted manual annotation, progresses through a semi-automatic stage enhancing mask diversity, and concludes with a fully automatic phase that capitalizes on model enhancements for generating high-quality masks at scale. This innovative approach to dataset creation allows SA-1B to provide an extensive training ground for SAM, contributing significantly to its advanced segmentation capabilities.
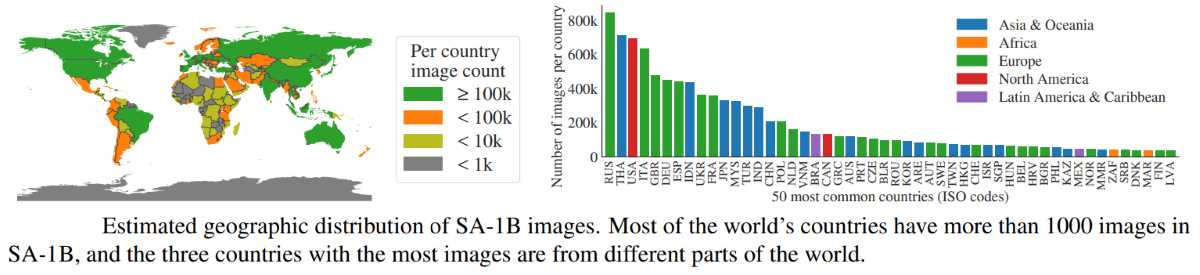
Furthermore, SA-1B's global distribution showcases a substantial increase in the representation of images from Europe, Asia, and Oceania, as well as middle-income countries. This contrasts with many open-source datasets and is designed to promote fairness and reduce bias in geographic and income distribution among the images. Every region, including Africa, is represented with at least 28 million masks, significantly more than what previous datasets offered.
By prioritizing diversity, size, and high-quality annotations, the SA-1B dataset not only enhances SAM's performance but also sets a new standard for future developments in computer vision segmentation models. Its contribution to the field is anticipated to be as significant as foundational datasets like COCO, ImageNet, and MNIST, providing a rich resource for developing advanced segmentation models.
One of the standout features of the Segment Anything Model (SAM) is its zero-shot transfer ability, a testament to its advanced training and design. Zero-shot transfer is a cutting-edge capability that allows SAM to efficiently handle new tasks and recognize object categories it has never explicitly been trained on or exposed to. This means SAM can seamlessly adapt to a broad array of segmentation challenges without the need for additional, task-specific training data or extensive customization.
The essence of zero-shot transfer lies in SAM's foundational training, which equips it with a deep understanding of visual concepts and relationships. This training strategy enables SAM to interpret and respond to a wide range of prompts effectively, making it an extremely flexible tool for various segmentation tasks. As a result, users can deploy SAM across different domains and scenarios with minimal effort, significantly reducing the time and resources typically required to tailor models to specific tasks.
This remarkable adaptability showcases SAM's versatility as a segmentation model, allowing for its application in diverse fields with varying requirements. Whether it's medical imaging, satellite photo analysis, or urban scene understanding, SAM's zero-shot transfer capability ensures it can deliver high-quality segmentation results without the conventional constraints of model retraining or fine-tuning for each new application.
With its numerous applications and innovative features, SAM unlocks new possibilities in the field of image segmentation. As a zero-shot detection model, SAM can be paired with object detection models to assign labels to specific objects accurately. Additionally, SAM serves as an annotation assistant, supporting the annotation process by generating masks for objects that require manual labeling.
Moreover, SAM can be used as a standalone tool for feature extraction. It allows users to extract object features or remove backgrounds from images effortlessly.
In conclusion, the Segment Anything Model represents a significant leap forward in the field of image segmentation. With its promptable segmentation task, advanced architecture, zero-shot transfer capability, and access to the SA-1B dataset, SAM offers unparalleled versatility and performance.
As the capabilities of Computer Vision continue to expand, SAM paves the way for cutting-edge applications and facilitates breakthroughs in various industries.
Inpainting refers to the process of restoring or repairing an image by filling in missing or damaged parts. It is a valuable technique widely used in image editing and restoration, enabling the removal of flaws and unwanted objects to achieve a seamless and natural-looking final image. Inpainting finds applications in film restoration, photo editing, and digital art, among others.
Stable Diffusion Inpainting is a specific type of inpainting technique that leverages the properties of heat diffusion to fill in missing or damaged areas of an image. It accomplishes this by applying a heat diffusion process to the surrounding pixels.
During this process, values are assigned to these pixels based on their proximity to the affected area. The heat equation is then utilized to redistribute intensity values, resulting in a seamless and natural patch. The repetition of this equation ensures the complete filling of the image patch, ultimately creating a smooth and seamless result that blends harmoniously with the rest of the image.
Stable Diffusion Inpainting sets itself apart from other inpainting techniques due to its notable stability and smoothness. Unlike slower or less reliable alternatives that can produce visible artifacts, Stable Diffusion Inpainting guarantees a stable and seamless patch. It excels particularly in handling images with complex structures, including textures, edges, and sharp transitions.

Stable Diffusion Inpainting finds practical applications in various fields.
In Photography
Stable Diffusion Inpainting stands out as a critical tool for photographers looking to enhance their images. It allows for the precise removal of unwanted objects, people, or blemishes, ensuring that the focus remains on the intended subject. This technology is particularly useful in professional photography, where image clarity and composition are paramount, enabling photographers to achieve a cleaner, more aesthetically pleasing outcome.
In Film Restoration
The role of Stable Diffusion Inpainting in film restoration is profound. Old and damaged films often suffer from missing frames, scratches, and other forms of degradation. This technology helps in meticulously restoring these films by repairing or reconstructing missing frames and removing visual artifacts. This not only preserves cultural heritage but also enhances the viewing experience for modern audiences.
In Medical Imaging
The application of Stable Diffusion Inpainting in medical imaging is revolutionary. It aids in the removal of artifacts that can occur during the scanning process, such as distortions caused by patient movement or machinery faults. By improving the clarity and quality of these scans, it contributes significantly to more accurate diagnoses and better patient outcomes. This technology is especially valuable in fields like radiology and oncology, where precise imaging can lead to early detection of diseases.
In Digital Art
For digital artists, Stable Diffusion Inpainting opens up new possibilities for creativity. It enables artists to seamlessly integrate different elements into their compositions, correct mistakes, or eliminate undesired elements without leaving any traces. This tool is invaluable for creating digital artwork, concept art, and even animations, where maintaining continuity and visual appeal is crucial. Artists can focus more on their creative vision, knowing they have the means to refine their work to perfection.

To achieve optimal inpainting results, consider the following tips:
Stable Diffusion Inpainting stands out as an advanced and effective image processing technique for restoring or repairing missing or damaged parts of an image. Its applications include film restoration, photography, medical imaging, and digital art.
With the Ikomia API, creating a workflow using Segment Anything Model (SAM) for segmentation followed by Stable diffusion inpainting becomes effortless, requiring only a few lines of code. To get started, you need to install the API in a virtual environment.
You can also charge directly the open-source notebook we have prepared.
For a step-by-step guide with detailed information on the algorithm's parameters, refer to this section.
Note: The workflow bellow requires 6.1 GB of GPU RAM. However, by choosing the smallest SAM model, the memory usage can be decreased to 4.9 GB of GPU RAM.

In this section, we will demonstrate how to utilize the Ikomia API to create a workflow for segmentation and diffusion inpainting as presented above.
We initialize a workflow instance. The “wf” object can then be used to add tasks to the workflow instance, configure their parameters, and run them on input data.
- ViT-H offers significant improvements over ViT-B, though the gains over ViT-L are minimal.
- Based on our tests, ViT-L presents the best balance between performance and accuracy. While ViT-H is the most accurate, it's also the slowest, and ViT-B is the quickest but sacrifices accuracy.
You can apply the workflow to your image using the ‘run_on()’ function. In this example, we use the image path:
Finally, you can display our image results using the display function:
First, we show the segmentation mask output from the Segment Anything Model. Then, display the stable diffusion inpainting output.
Here are some more stable diffusion inpainting outputs (prompts: ‘dog’, ‘fox’, ‘lioness’, ‘tiger’, ‘white cat’):
In this tutorial, we have explored the process of creating a workflow for image segmentation with SAM, followed by stable diffusion inpainting.
The Ikomia API simplifies the development of Computer Vision workflows and provides easy experimentation with different parameters to achieve optimal results.
To learn more about the API, refer to the documentation. You may also check out the list of state-of-the-art algorithms on Ikomia HUB and try out Ikomia STUDIO, which offers a friendly UI with the same features as the API.
[1] https://github.com/facebookresearch/segment-anything
[2] https://github.com/runwayml/stable-diffusion










.svg)


