
Kandinsky AI: Leading the Way in Advanced Text-to-Image Generation

The Kandinsky AI series represents a significant advancement in the field of AI-driven text-to-image generation. This model series, developed by a team from Russia, has evolved through several iterations, each bringing new features and improvements in image synthesis from text descriptions.
Kandinsky 2's models, a culmination of several evolved versions, marks a pivotal moment in AI-driven image synthesis. Latent diffusion models, central to Kandinsky 2, revolutionize text-to-image generation by creating images in a latent, compressed space, then meticulously refining them to achieve intricate detail.
This method, offering enhanced control and creativity, empowers Kandinsky 2 to effectively transform complex textual prompts into vivid, detailed images.
This advancement not only elevates the quality and versatility of AI imagery but also signifies the model's prowess in producing highly realistic and contextually accurate visuals.

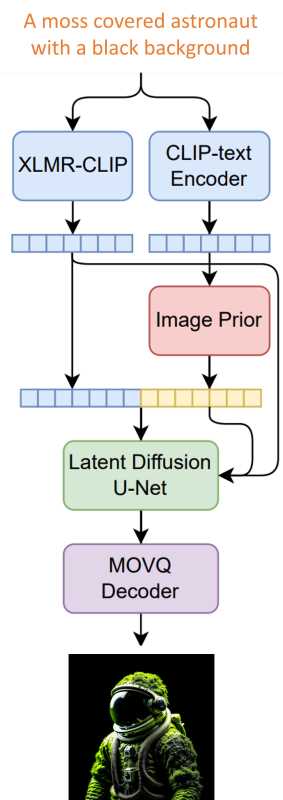
Kandinsky AI 2.0 marked its significance as the first multilingual text2image model. It was notable for its large UNet size of 1.2 billion parameters and incorporated two multi-lingual text encoders: mCLIP-XLMR with 560M parameters and mT5-encoder-small with 146M parameters.
These encoders, combined with multilingual training datasets, opened up new possibilities in text2image generation across different languages.
Kandinsky AI 2.1 was a leap forward, building upon the solid foundation laid by its predecessor. It was recognized for its state-of-the-art (SOTA) capabilities in multilingual text-to-image latent diffusion.
This model leveraged the strengths of DALL-E 2 and Latent Diffusion models, incorporating both CLIP visual and text embeddings for generating the latent representation of images.
The introduction of an image prior model to create a visual embedding CLIP from a text prompt was a key innovation. Additionally, the model used an image-blending capability, allowing the combination of two visual CLIP embeddings to produce a blended image.
One of the significant architectural changes in Kandinsky 2.1 was the shift from VQGAN generative models to a specifically trained MoVQGAN model. This allowed for improved effectiveness in image generation. With 3.3 billion parameters, including a text encoder, image prior, CLIP image encoder, Latent Diffusion UNet, and MoVQ encoder/decoder, Kandinsky 2.1 demonstrated notable improvements in image synthesis quality.
Kandinsky 2.2 brought further enhancements, primarily through the integration of the CLIP-ViT-G image encoder. This upgrade significantly improved the model's ability to generate aesthetically pleasing and accurate images.
Another notable addition was the ControlNet mechanism, allowing for precise control over the image generation process and enabling the manipulation of images based on text guidance.
Kandinsky 2.2 was designed to be more adaptable and versatile, capable of generating images at various resolutions and aspect ratios. This model was trained on a mixture of datasets, including the LAION HighRes dataset and a collection of 2M high-quality, high-resolution images with descriptions, thereby enhancing its performance in generating more aesthetic pictures and better understanding text.
The Kandinsky 2.2 model includes a range of variants catering to different image synthesis needs:

Transforms an input image according to new text specifications.

Combines elements of different images based on textual guidance.

Allows precise control over the image generation process, tailored by text inputs.

Edits or completes parts of an image based on textual cues, useful for restoring or modifying images.

Each variant leverages the core strengths of the Kandinsky 2.2 model, offering flexibility and creativity in image synthesis tasks.
The Kandinsky 2 series, particularly versions 2.2, have wide-ranging applications. They can be used in design for rapid conversion of textual ideas into visual concepts, streamlining the creative process. In education, these models can transform complex textual descriptions into visual diagrams, making learning more engaging and accessible.
Using the Ikomia API, you can effortlessly create images with Kandinsky 2.2 in just a few lines of code.
To get started, you need to install the API in a virtual environment [2].
You can also directly charge the notebook we have prepared.
Note: This workflow uses 11GB GPU on Google Colab (T4).

• model_name (str) - default 'kandinsky-community/kandinsky-2-2-decoder': Name of the latent diffusion model.
• prompt (str) - default 'portrait of a young women, blue eyes, cinematic' : Text prompt to guide the image generation .
• negative_prompt (str, optional) - default 'low quality, bad quality': The prompt not to guide the image generation. Ignored when not using guidance (i.e., ignored if guidance_scale is less than 1).• prior_num_inference_steps (int) - default '25': Number of denoising steps of the prior model (CLIP).
• prior_guidance_scale (float) - default '4.0': Higher guidance scale encourages to generate images that are closely linked to the text prompt, usually at the expense of lower image quality. (minimum: 1; maximum: 20).
• num_inference_steps (int) - default '100': The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference.
• guidance_scale (float) - default '1.0': Higher guidance scale encourages to generate images that are closely linked to the text prompt, usually at the expense of lower image quality. (minimum: 1; maximum: 20).
• height (int) - default '768: The height in pixels of the generated image.
• width (int) - default '768: The width in pixels of the generated image.
• seed (int) - default '-1': Seed value. '-1' generates a random number between 0 and 191965535.
Note: "prior model" interprets and encodes the input text to understand the desired image content, while the "decoder model" translates this encoded information into the actual visual representation, effectively generating the image based on the text description.
In this article, we've explored the innovative world of image creation using Kandinsky 2.2, a versatile AI model.
With Kandinsky 2.2, you can easily engage in various image synthesis tasks such as image-to-image transformation, image fusion, inpainting, and even ControlNet, all through a few lines of code with the Ikomia API.
If you're seeking more cutting-edge diffusion models, consider exploring Stable diffusion XL and SDXL Turbo, notable competitors in the open-source domain.










.svg)


